So basically the whole reason I created this blog is because the answer to this question hit me like a brick and I wanted a place to instantly record it and refer back to in the future. I really couldn’t care less about followers and what not right now but who knows what the future holds? I was also thinking of shifting my life’s daily course of events from a stream of meaningless hours spent on Instagram, YouTube and memes to one that hopefully has a more positive impact on my life.
So here we go. I was watching one of Andrew Ng’s lectures on the mathematics and logic behind CNNs (Convolutional Neural Networks) and he explained things in a way that managed to snap everything into place for me. So get this:
When dealing with machine learning in general, your data set is viewed as a collection of “data points” that have “features” associated with it. For instance, the features of a house could be values like “Number of bed rooms” or “area” or “number of windows” etc. When dealing with Neural Networks, you talk about its “depth” i.e, how many layers it possesses. Here’s the catch, if your data set has too many features per data point and not enough data points, it so happens that during training your neural network will adapt too well. It memorizes the training data and fails to generalize well. The result? A NN that performs poorly on new (test) data points.
When you talk about the problem of Image Classification, your data points are your individual images. Unlike in the case of traditional problems like that of predicting house prices, the features of each image are the RGB values of it’s pixels. i.e, each pixel is a feature! In an age where even our smartphones are able to shoot in 4K, can you imagine how much information is out there, just waiting to be processed?
A 1000 x 1000 RGB image would mean each data point is 1000 * 1000 * 3 (since there are 3 color channels) = 3,000,000 feature data point! You’d need an absurd number of data points to overcome the over-fitting problem if you were to use a traditional neural network.
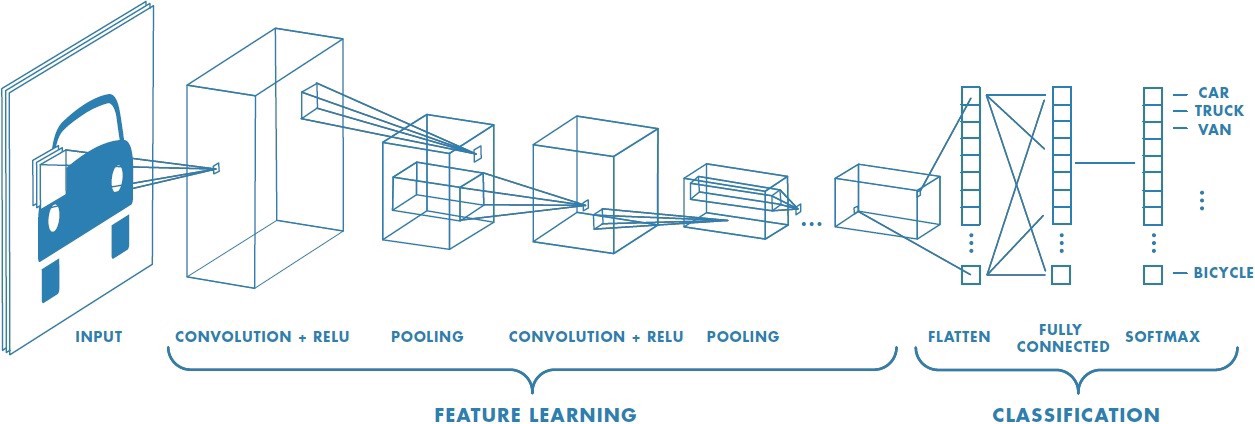
Enter, Convolutional Neural Networks. The beauty of a CNN lies the concept of “kernels”, which are generally 3×3 or 5×5 matrices that you “convolve” over your image. I’m not gonna explain the specifics of how kernels work (I’ll leave some helpful links at the end) but it goes something like this:

So basically while a traditional neural network would have resulted in 3M * (number of neurons in the next layer) number of parameters per layer, a CNN reduces it to a mere (f * f * c + 1) * N
Where:
f = Size of the filter (3, 5 etc)
c = Number of channels (3 for RGB)
1 is added for the bias term
N is the number of filters used in the layer
And this parameter count is independent of the image size, since the kernel slides, or “convolves” over the entire image, f x f pixels at a time. This is one of the major reasons we choose CNNs for Image processing tasks over regular NNs.
Thanks for reading! If you’d like to know more about CNNs I highly recommend taking up Andrew Ng’s course on the same on coursera, or reading this medium post. Good luck!
